There’s this book called The Art of Doing Science and Engineering by Richard Hamming that’s about the art of doing science and engineering. Well, maybe 40% of it is, and the rest of it is full of equations and formulas on forier transforms and 100 other things that go above my head.
It’s a pretty good book nonetheless. There’s a section where Hamming reflects:
A psychologist friend at Bell Telephone Laboratories once built a machine with about 12 switches and a red and a green light. You set the switches, pushed a button, and either you got a red or a green light. After the first person tried it twenty times they wrote a theory of how to make the green light come on. The theory was given to the next victim and they had their twenty tries and wrote their theory, and so on endlessly. The stated purpose of the test was to study how theories evolved.
But it turned out that the device was completely random. There were no patterns. The participants were not statisticians and no one figured out the trick to the machine.
This is a sad commentary on your education. You are lovingly taught how one theory was displaced by another, but you are seldom taught to replace a nice theory with nothing but randomness! And this is what was needed; the ability to say the theory you just read is no good and there was no definite pattern in the data, only randomness.
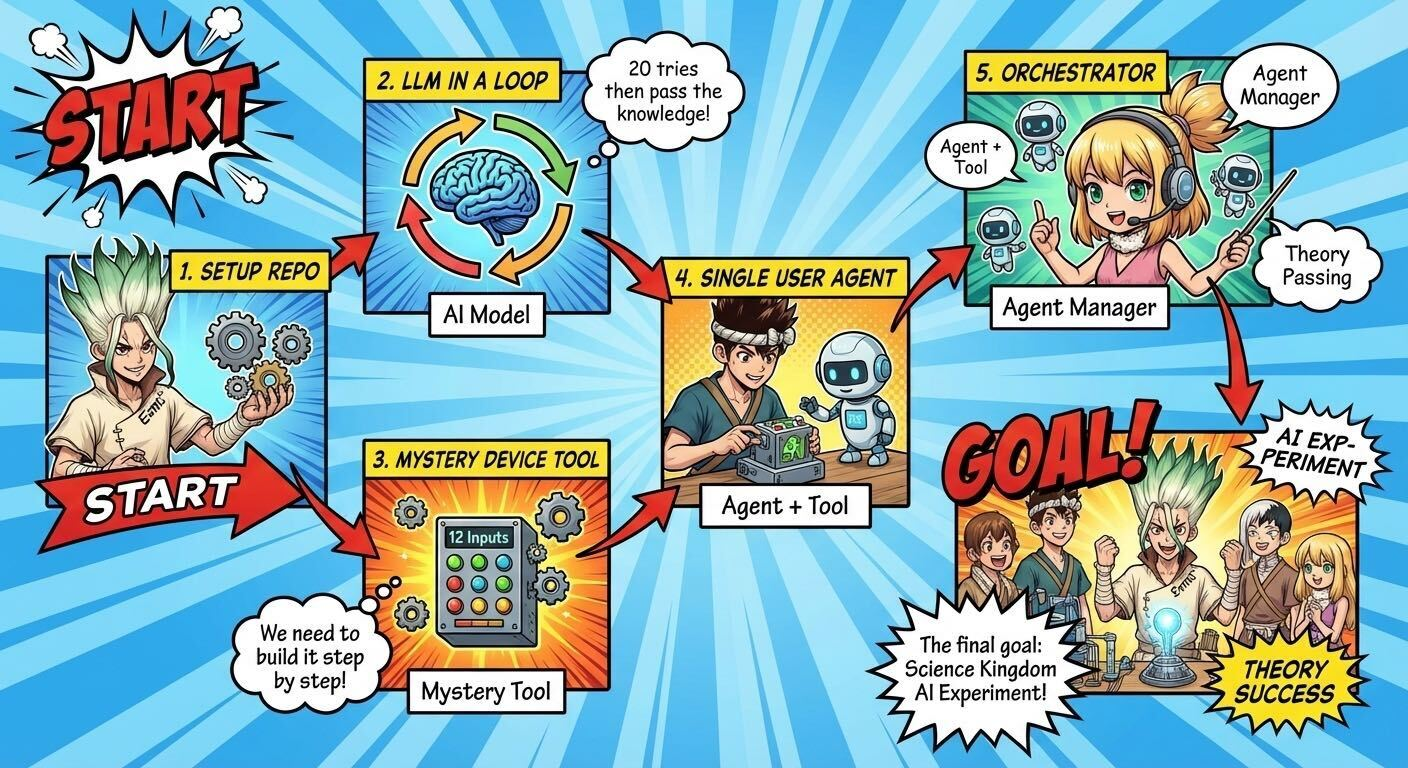
And so Hamming’s “friend” 1 proves that human beings have a hard time accepting randomness. But what about LLMs? If we put some models through this same test, would they be able to hive-mind through and reach the disappointing conclusion? Or will each prior attempt pollute the context of each agent that comes after it? Let’s find out.
The Experiment
I’m not so much interested in the outcome of this experiment as I am in how a simple tool call can influence the behavior of an agent loop over multiple iterations.
To start:
The architecture of this experiment is very simple: we’ll create a mystery tool to represent the box of switches, equip an Agent2 with it, and then run an orchestrator to speed run Orb: On the Movements of the Earth and pass the output from each agent to the next.
Create the tool
Create the Agent
We’ll want to add a few guardrails to make sure the agent doesn’t abuse the tool. Instead of relying on the LLM to not cheat, we’ll control the context from outside of the loop:
Create the Orchestrator
Initial Results
| Model | Agent 1 | Agent 2 | Agent 3 |
|---|---|---|---|
| Gemma 3 12b | The light turns green when switches 1–4 follow a specific alternating true/false sequence, with all other switches irrelevant and an all-true configuration failing. | The light turns green from alternating true/false patterns over switches 1–8, where length depends on the device’s initial state and switches 9–12 have no effect. | The light turns green following an alternating true/false pattern across all switches, with both 1–8 and 9–12 alternating when used, and an “even number of trues” rule that allows all-true to succeed. |
| GPT 5.2 | The light turns green if any of switches 5, 6, 7, 8, 10, or 11 is on, except when both 9 and 12 are on (which fails unless 5 or 6 overrides it). | The light turns green if any of switches 2, 4, 5, 6, 7, or 12 is on, but pairs 7+12 and 9+12 cause failure, with 9+12 fixable only if 5 or 6 is also on. | The light turns green when any of switches 1, 3, 4, 5, 7, 8, or 12 is on, except for failures from 9+12 (unless 5 or 6 present) and the trio 6+7+12. |
| Opus | The system divides into zones: switches 1–3 block success, 4–5 are reliable triggers, 6 works only with 10–12, and 8–9 cause failures; success by keeping 1–3 off and activating 4, 5, or 6+10–12. | The device is more permissive than thought—even all-off succeeds—but switch 1 blocks it; many switches work alone, with failures from specific pairings rather than a simple good/bad split. | Success hinges on knowing which switches work alone (4, 6, 8, 9, 10, 11, 12) and which need partners, with complexity from forbidden combinations involving 7, 9, and 10. |
All models are equally bad.
Footnotes
-
I found zero evidence that this experiment actually existed. ↩