Controlling Browsers with LLMs
The one where I look at how the playwright MCP works
When playwright announced their official MCP server, the first thing I tried was setting it loose on one of the applications I’m developing. The results were good—really good.
Look at this example (not my application) where I simply ask:
Visit https://factoriolab.github.io/spa?v=11 and select the legendary preset
Claude then:
- Opens up a new browser using the
browser_navigate - Takes a snapshot to “see” the page
- Immediately recognizes there’s a welcome page and clicks through.
- Sees the preset, tries to click it, and realizes it’s outside of the viewport.
- Then ultimately runs out of context and quits.
There are a couple of really interesting things in this example. In this particular application, the “preset” dropdown is hidden on smaller viewports. If it didn’t run out of tokens, I expect it would have been able to navigate the “mobile-friendly” design on it’s own.
These are the types of end-to-end tests I hate having to write and maintain. Throwing a LLM at a browser won’t ever replace a solid E2E suite, but there’s an enormous amount of potential for new applications here. The Claude Desktop + Playwright MCP example shows you can get pretty far with little effort. Until you run out of context. So how do I download more context? How can we make a session run long enough to complete an E2E flow?
We’re gonna need to build our own agent. To do that, we need to understand what just happened. How does this actually work?
inb4 LLMs cant “see”
When Claude says stuff like “Let me take a snapshot to see the page content more clearly.” and “I see the main interface now”, what is it talking about? How does it “see”? Your first assumption might be “it’s taking a screenshot of the page and interpreting the image.”
Not quite.
Unless you explicitly use the --vision flag, the Playwright MCP will actually use aria snapshots instead of images. My example above is not using vision.
Let’s step back for a second and think about this. How could an LLM interpret a webpage? One way would be to take a picture and then describe the picture. For follow up interactions, it would need some concept of a coordinate system (click x,y).
Another way would be to just pass text and interpret that. Websites are just text after all. For follow up interactions, it would have direct access to the elements on the page. So we should be able to just view source and have the LLM interpret that.
And we can. Except it would cost a fortune.
everything is token
When you use services like claude.ai or the Claude Desktop app or chatgpt.com, you don’t really care about tokens or API costs. You get an all-you-can-eat-ish pricing model. Instead of paying per token, you pay per month. It’s a great consumer model, you don’t have to worry about input tokens and context length. Except when you abruptly get cut off or rate-limited because your chat got too big.
Under the hood, my MCP chat session is still calling the Claude LLM. I enter a prompt, then the LLM responds. Sometimes, the LLM will respond with it’s own prompt, and the user responds (indirectly by executing tools). For each turn, the entire conversation history (the context) is maintained and passed back and forth because the LLM has no concept of memory.
This history, or context, is measured primarily as input tokens. And tokens are more or less just words, or parts of words, or groups of characters, or whatever1. The more tokens you have, the bigger your payload, the more money you pay.
And there is a hard ceiling to the total number of tokens your conversation can have. And it’s 200k (ish) for Claude. For our scenario, output tokens barely make a dent.
You pass along the entire conversation in each call so if your first call adds 20k input tokens, your second call will add 20k + whatever you just added. Third call adds 20k + 4k + maybe another 2k and so on. (Applications like Claude.ai use a rolling “first in, first out system”)
| Turn | Input Tokens (This Turn) | Cumulative Context Size (Tokens) |
|---|---|---|
| 1 | 800 | 800 |
| 2 | 15000 | 15800 |
| 3 | 500 | 16300 |
| 4 | 20000 | 36300 |
| 5 | 1000 | 37300 |
| 6 | 25000 | 62300 |
| 7 | 300 | 62600 |
So if we want to be able to execute an entire E2E flow, we’ve got a context problem. What’s the most efficient way for an LLM to “see” a webpage?
Text vs. Vision
HTML
Right off the bat, it’s absolutely not sending the entire source of the page. If we take the entire rendered HTML of this application, it comes out to 167,325 characters / 48,423 tokens. We aren’t writing artisanal Zeldman HTML anymore. Modern websites are massive.
We could certainly strip out some of the junk in the markup and run it through a preprocessor but even if we halved it, that’s still 24k tokens.
Images
Okay so what’s it look like if we took a picture? For the vision approach, Playwright will take a visual screenshot and return it as a base64 encoded image that is then sent to the API to interpret. The request looks something like
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "toolu_01YZELPTqYQjKACBRtqJtoL5",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"data": "/9j/OVzXSsDdrh07OlbREFB7WT1NK5sLtG0uvmYQBs2KWiYY9OC0tGlcWi1tmzcrSICIiAiIg+WfCX/wBQVv8AqKXDa2ilwx+GYkZI4tJpYpoxcsdaxuOkKL4S/wDqCt/1Fq17oi9MPHM2mXV0kOGy4bV4VhVYZKuoDXF8rMglym+Vt93/AN9HKkFpIO8bCi8ViLJM3fSPg/8A4HSfU/NbFa74P/4HSfU/NbFeSr3l6Y9hERRRERAREQEREBERAREQEREBERAREQEREBERAREQEREBERBjW/NGfW96hw/5Z/1D+SmrfmjPre9Q4f8ALP8AqH8lhtYREW2BERAREQEREHm9cnjHwfhp6rXGxPkpbkviZ/lPH6vGy61eK01TCTF3C3NZO8SNjMTQ15fICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiDOSbQUwda53BY01UZ8zXNAIF9iwrfmjPre9Q4f8s/6h/JYbWERFtgREQEREBERAWkxnG2UsgpIJGNmcbOlf5EV+Pb2K1jNc+jpctOwyVMt2xNAue0+hciyShkpZHFtfUR7XTsL2eI7pdYi4779i3TTfrKTLNzZI61+lD3xyx5aovka9wBPlf8ATxtussKKjc6nlip4TVRv8WSbMWQggNzs+rsYyMWY1rRwAssl8mRNnubvZ9ZRfJkTZ7ru9n1lFx3wL/8Ae/8AZ/8AJdQvj+J8dsas6eN7d+38nr09LOmKrrKKsi8/xX/4/r/435fusoqyJ8V/+P6/+Hl+6yirInxX/wCP6/8Ah5fusoqyJ8V/+P6/+Hl+6yirInxX/wCP6/8Ah5fusoqy5L4ZfOqb6h/FenwvjfMasaeNvu56unt05Xdsi+TIvr7Pd5d3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz
BLAH BLAH BLAH SOOOOO MUCH MORE GIBBERISH
3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6yi+TImz3N3s+sovkyJs9zd7PrKL5MibPc3ez6vW/NGfW96hw/5Z/1D+Sipf/TuH/6Uf/ipcP8Aln/UP5LzT7u8PlyIi97xCIiAiIgIiICIiAisxUcstFNVty6OFzWuudtzuTU5fi81vi6ISaPftva6XgsrIiICIiAiIg6j4F/+9/7P/kuoXL/Av/3v/Z/8l1C/I/4n/uq/t/aH1vDf6UCLxVPjGEyFjGzPAdlL2xOLQe9eGmiqr2h2mYj3FhZWiAAAAAAAABimQAAt4UAABjaWFlaIAAAAAAAACSgAAAPhAAAts9YWVogAAAAAAAA9tYAAQAAAADTLXBhcmEAAAAAAAQAAAACZmYAAPKnAAANWQAAE9AAAApbAAAAAAAAAABtbHVjAAAAAAAAAAEAAAAMZW5VUwAAACAAAAAcAEcAbwBvAGcAbABlACAASQBuAGMALgAgADIAMAAxADb/2wBDABALDA4MChAODQ4SERATGCgaGBYWGDEjJR0oOjM9PDkzODdASFxOQERXRTc4UG1RV19iZ2hnPk1xeXBkeFxlZ2P/2wBDARESEhgVGC8aGi9jQjhCY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2NjY2P/wAARCAMgBQADASIAAhEBAxEB/8QAGwABAAIDAQEAAAAAAAAAAAAAAAMEAgUGAQf/xABREAABAwICBgQIDAQEBQQCAgMBAAIDBBEFEhMUITFRkUFSYXEWIjJTgZKh0QYVMzRlcqKjscHS4iNUY+E1QnOTJFVigrI2RMLwQ/GU0wclRf/EABoBAQEBAQEBAQAAAAAAAAAAAAABAgMEBQb/xAA1EQEAAQMDAgQGAAQHAQEBAAAAAQIREgMTUSFhBBQiMRVBUoGR8DJxobEFIzM0wdHhYkLx/9oADAMBAAIRAxEAPwDskRFtgREQICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiDOSbQUwda53BY01UZ8zXNAIF9iwrfmjPre9Q4f8s/6h/JYbWERFtgREQEREBERAWkxnG2UsgpIJGNmcbOlf5EV+Pb2K1jNc+jpctOwyVMt2xNAue0+hciyShkpZHFtfUR7XTsL2eI7pdYi4779i3TTfrKTLNzZI61+lD3xyx5aovka9wBPlf8ATxtussKKjc6nlip4TVRv8WSbMWQggkrxaQxkxsjbUaN7QN7mjpN+hY4HRz4viTY8Qgs2nOaaRzMr5Oq1/Fc092dxe7eTf0ru/g9RtbgcdRUBz5Jy6RxLjc8F3r9NLnROUthVwMhqpXRttexIG7kjI45J4AWtc1x27N+xe5RncR0gDffoWEfj1LBI0NjjfvDuhfnoqv4m/E+73Wtp/wA0jPg/S00rpxPVyAbWxSzudG30LUfB+ipasYrGZ5H/AMW92kMLTxaWm631VS0lXCYjTvmaegl1vxVVmB0UJEsdBTU5aPLuQRyX1PM0W6Xn+UfsOG3KxheE09JFnL56h7xtdUSGQjsF9ymhbSsi8dkYNzsttUWWmghYZa6NkbvJvIAD3ElW2UkFgQMwPSTdc6tTXq/hpt/Of+IaimiPeWpxOjpcQoJqUxAOcS5jwLFp6CuIiqNUqY6enog2e+STpe93SGk+SD2L6m1jG+S0DuC4L4XPqMNxeQ0shibVtD3Fo23Gw7V6PDbt5jUm7nq4x1htfgzUjRTURkjeYHbDGbtAPQO7ct4uH+C9fM/GI45HBwLCwWaB29C7hda4tLFM3hXrqyOgpX1EocWM3ho2qOixGCtodbizCMXvmABFlW+E3+B1HcFozK+jiqMNZcGqyGPucNqRTeEmq0t7R45DX09RJSQTPdCPIIALu6xKxmxh8EVE6Wjcx9S7KWOdYs9m32LUUUTYYMaiaLBgt7FBUuczB8GdGzO8O8VvErWMXTKbO0Rcthry6DEKyUuOJsBDmuG2MdFlRoaatlhgq6akdps+Z1VrQ8cX2gtJUw7rm7GqqNWgMuilmt/kibmcfQtZD8IoZpjFHQV5e02cNCPF79uxbht8ovsNtq0OCgHG8VB3F6zFrTdZvdvl6uLex2lmwXaBJU3H1bXU2GOdXYjQ07too2uzd4OxawTN0FNXufFUS1VM+lZC4i7/APMOO5TmrgFJrRktBlzZyDuXKQxMkwTGC4E5JS4WJG1Tz4dSRfBR00UdnvYHuIe7ae66TTBlLqIpGTRtkjN2OFweIWa5efCYGfB5k9JHlmYGzXDibkb96kwyQYxjYrN8dNEAPrHepj81y+TpFrXY1TMxUYe5sgmOwOsMv4rZLkMTjccXr52Xz07WSD0HapTET7lU2b7EsZpsMliinbI50m4MANu+5UtfiMOH0gqJg8tJADWgEm65XEpRiGlr97NLHHH+JV/G6nSYnRU2hmnZCBJIyFmZx9C1hHRnL3b2lroquhFXEHaOxNiNot0Jh9dFiNKKiFr2sJIs8AHZ3LRYFU5RiNG6OSIWdIxkrcrgCOCu/BP/AAVn13fipNNrtRVduSQASTYBak/CCmMjhFBVTsabOliiuwHvVzFA92G1Ajvm0ZtZU/g1JD8Rw5XNGQWft3HtUiItcmetklXjcNLUsp9WqppHMzhsMYcbc1YZXsNC6rkimhY0ElsrcrhbsWmr9aPwqj1HQ6XQG2mvlt6F78IaipbhkNLOGuqZ32c2nBNx2A7VrGOiZT1bXC8VgxSN74GyNyGxbIAD7Cry5XDKkU/wgDBT1FPFURhobPHkJcOldUs1RaVpm8CIiy0IiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICLxeoCIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgIiICIiAiIgxrfmjPre9Q4f8s/6h/JTVvzRn1veocP+Wf8AUP5LDawiItsCIiAiIgLX49/glX/plbBVcTi0+G1Edr5ozsVj3SfZ8wPknuX0SDLDgNCTJIA9gaA3bv7FyNI7D5SWRUsMcm688rnE7NuVo2Xv0bV02EtlrMCoyx5MlO4gRuAG1vQVvxEzNPRjSizYNaWxhrTtG4lTUk9PSx5NHLpHO2NPjlx7CqsMmeZxDHWI3noPAqSUXjdtaNlwXbgvzWnq1aFfqi930Zpium8N0DcA2t2KljJthVR/HMIyEF4ZmPdZVWtxIULJKeaGIhty2Rhf6b3WtrKr4SRsc18VPJG4WvE3bY9hK+5GpTH8U2/n/wB+zyTdz1JMWuYKdlrR5S0Uos4f9wO3uXU/BvF4NBFQzSETBpLMzgcw4bNxHBco9rGEMqX1FMb/AOZlvxW0wsMp5dLT18uYi1zG12zkvXVEVReHGmZiWzirq+TFgYXVD43PIImaI2Bv/T0k9q13/wDkEDTUR6bOW2bTS1VVFUuxCoMsYIYRC0AX7LbVoPhTG+oxSOnmr7iKMXklYBZztzbNHSs0Wyhqq+MtV8Hv8cpPrr6OuF+D+HSxY1TmbR3GZ2VsgcRbpNiu6V1ZvLOnFoQ1NNDVwOhnZnjdvFyPwUbsOpHVEM7oQZYRZjrnYPzUeMVklBh0tREGl7NwcNi10OMYhDNSCuipjFVeSYS4FvfdYiJt0amYv1bRuG0jdPaL5x8p4x8b27PQsThVEYoIzD4lObxjM7xTz2qtR4gWy176msjkihdubGQYx27NvtUrMdwySdsLKthe7cLG3O1ktUXhY1Cm1w1eitORlLg4i47RuKrjAsMFQJxSNEgN7hxtfuvZS1uK0VA5raqobG524WJPsVHGsTfFh8FRQTttJIBmABuPSkZE2bpV4KKnp55Zoo8skxu85ibrXMrqk/CNtIZP4BgD8uUb7cd6sHHcMFRq5q2iS9rEG1++1ktK3hOcPpTXCtMQ1gC2e5/DclNh9LSzyzwRZJJfLdmJvzUdZi9BQyCOpqGseRcCxJ9gVqGWOeJssTg5jhcEdKnWx0Qw4dSQxzRxwgMmN5ASTmPpUdPhFBTQyxQ04Ecux7S4m/MqkMTr66qmjwuGn0UJyuknJs48BZXnVzaOiZNib44HneGkkX7OkqzFSdFeShGGUj2YTQNkdLsc0y2A7fGKYRhbqHC3wOc1s0ty4tFwCfcrNPilFUwPngna+OMXcQDcejejsTo20TawzWgcQA/Kdt+y10vPsWj3ZYbRNw+iZTtdmy7S61sx4r3UKYzTSmK75m5ZCSfGCjqMVoaV4ZPUNjcW5wCDtCxbjNBJRyVUVQ18ce/g3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl1GR3VPJMjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/8A2p4ffRn3/wC1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl1GR3VPJMjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXVRtcHi7TyVlcZ4ffRn3/wC1PD76M+//AGptV8G5Ty7NFxnh99Gff/tTw++jPv8A9qbVfBuU8uunBIFgSocjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/8A2p4ffRn3/wC1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl1GR3VPJMjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/8A2p4ffRn3/wC1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl1GR3VPJMjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/8A2p4ffRn3/wC1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl1GR3VPJMjuqeS5fw++jPv/wBqeH30Z9/+1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/8A2p4ffRn3/wC1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+/wD2p4ffRn3/AO1Nqvg3KeXUZHdU8kyO6p5Ll/D76M+//anh99Gff/tTar4Nynl10AIBuCFKuM8Pvoz7/wDanh99Gff/ALU2q+Dcp5dmi4zw++jPv/2p4ffRn3/7U2q+Dcp5dmqOIYRQYkP+LpmPd0PGxw9I2rmvD76M+/8A2p4ffRn3/wC1WNOuPYnUoled8CMLLriSqaOAe234K/Q/BvC6F4fHTB8g3PlOYj8lovD76M+//anh99Gff/tVmnVlmKtOHZouM8Pvoz7/APanh99Gff8A7Vnar4a3KeXXjp7z+KO8k9yhoajW6GCpy5NMwSZb3tcXtdTO8k9y5uj/2Q==",
"media_type": "image/jpeg"
}
}
]
}
]
},The base64 image itself is roughly 30,612 characters / 17,109 tokens. But wait, isn’t that a lot of tokens?
Yes. Base64 images aren’t human-readable. This visualization may help.
Luckily, we don’t pass images as text strings. Instead, we use the image type in our API call. This tells the LLM (if its multimodal) it’s not dealing with text. For Claude, image tokens are calculated a little differently:
If your image does not need to be resized, you can estimate the number of tokens used through this algorithm: tokens = (width px * height px)/750
So for us, our (1280*800)/750 image comes out to roughly 1,365 input tokens. That’s significantly cheaper. That’s also 1,365 tokens no matter what the content is, as long as the size remains the same.
Does this mean images are the way to go? Not necessarily. Using screenshots can sometimes be less accurate. It all depends. When I try my example using vision mode, the LLM has a hard time translating the exact coords for the skip button.
Maybe a little extra prompting could help here, but accuracy in general is a real concern. A 1k snapshot isn’t more efficient than a 5k snapshot if the model has to make 6 additional follow up calls because it missed the exact element.
It all depends.
The Accessibility Tree
Luckily, there’s a third option. Chrome exposes a complete accessibility tree which represents how the page appears to assistive devices.
This representation is lighter and much more semantic and is baked right into the browser so no extra parsing is needed.
And Playwright exposes this with a very helpful ariaSnapshot method. If we revisit our first example, when Claude calls the browser_snapshot tool, the response it gets back is an aria snapshot.
- generic [ref=s2e3]:
- generic [ref=s2e5]:
- generic [ref=s2e7]:
- generic [ref=s2e9]:
- generic [ref=s2e11]:
- generic [ref=s2e12]:
- img "FactorioLab" [ref=s2e14]
- generic [ref=s2e15]:
- text: Welcome to
- text: FactorioLab
- text: "! Let's get to work."
- generic [ref=s2e18]:
- combobox "options.game.factorio" [ref=s2e19]:
- generic [ref=s2e20]: Factorio
- button "dropdown trigger" [ref=s2e23]
- generic [ref=s2e27]:
- combobox "Space Age" [ref=s2e28]
- button "dropdown trigger" [ref=s2e29]
- button "Add items" [ref=s2e32]: Add items
- button "Add machines" [ref=s2e34]: Add machines
- generic
- generic
- separator
- button "Load last state" [ref=s2e43]: Load last state
- separator
- button "Help me get started" [ref=s2e48]: Help me get started
- button "Skip" [ref=s2e50]: Skip
- generic [ref=s2e52]:
- generic [ref=s2e53]:
- checkbox
- text: Don't show this screen again
- text: FactorioLab 3.13.4
- generic:
- genericand it’s all roughly 1,301 characters / 362 tokens.
So Playwright made a very smart call to make this the default mode for generating snapshots for the LLM to see what’s on the page. For most cases, we probably don’t need vision snapshots. The reality is that It Depends. Mostly on the complexity of the layout and the task at hand.
Refs
Aria snapshots might be a great way to “see” the page, but now there’s a new problem with how to interact with the page. The LLM can’t simply just say Click button "dropdown trigger". There could be multiple elements that match criteria. The accessibility tree is an abstraction and so we need a translation step somewhere. Traditionally, E2E tests are written using very specific selectors, either data-testid attributes or unique ids to solve this problem. To make it even more difficult, elements like <input type="submit"> can show up in the accessibility tree as button.
The LLM doesn’t know anything about the actual markup, css, attributes, or xpath. Including any of those things would cost input tokens. Trying to click the wrong selector can be costly—not only does it waste time, it also adds another message to the conversation history, just like when the vision model gets the wrong coordinates.
To make the accessibility tree truly useful to the LLM, we need unique selectors so the LLM can accurately interact with elements with precision. One solution—before returning the snapshot, we could create our own unique IDs and append them to each element using a custom aria-ref attribute and return them in the snapshot.
As of v1.52 , this is exactly what Playwright does under the hood for you. If you noticed in the above example, every interactive node contains a ref=sXeXXX id. These are much more lightweight than trying to use actual CSS or xpath.
A note about other tools
Using aria snapshots isn’t anything new or specific to Playwright. Other similar tools like Puppeteer also include snapshot()methods. The key difference is that Playwright exposes this synthetic ref system for you out of the box, which makes it a clear winner for our use case of LLM automation. I can almost guarantee other tools will be adopting the same feature in the future.
Time to build
Now that we understand what’s going on, we can begin to think about building our own version. Because we have no control over the context when using MCP clients like Claude Desktop, we won’t be able to complete a full end-to-end flow without building our own agent. It’s clear—we need more control over managing the context and determining which mode to execute. Also, it’d be great to run this headless.
To recap:
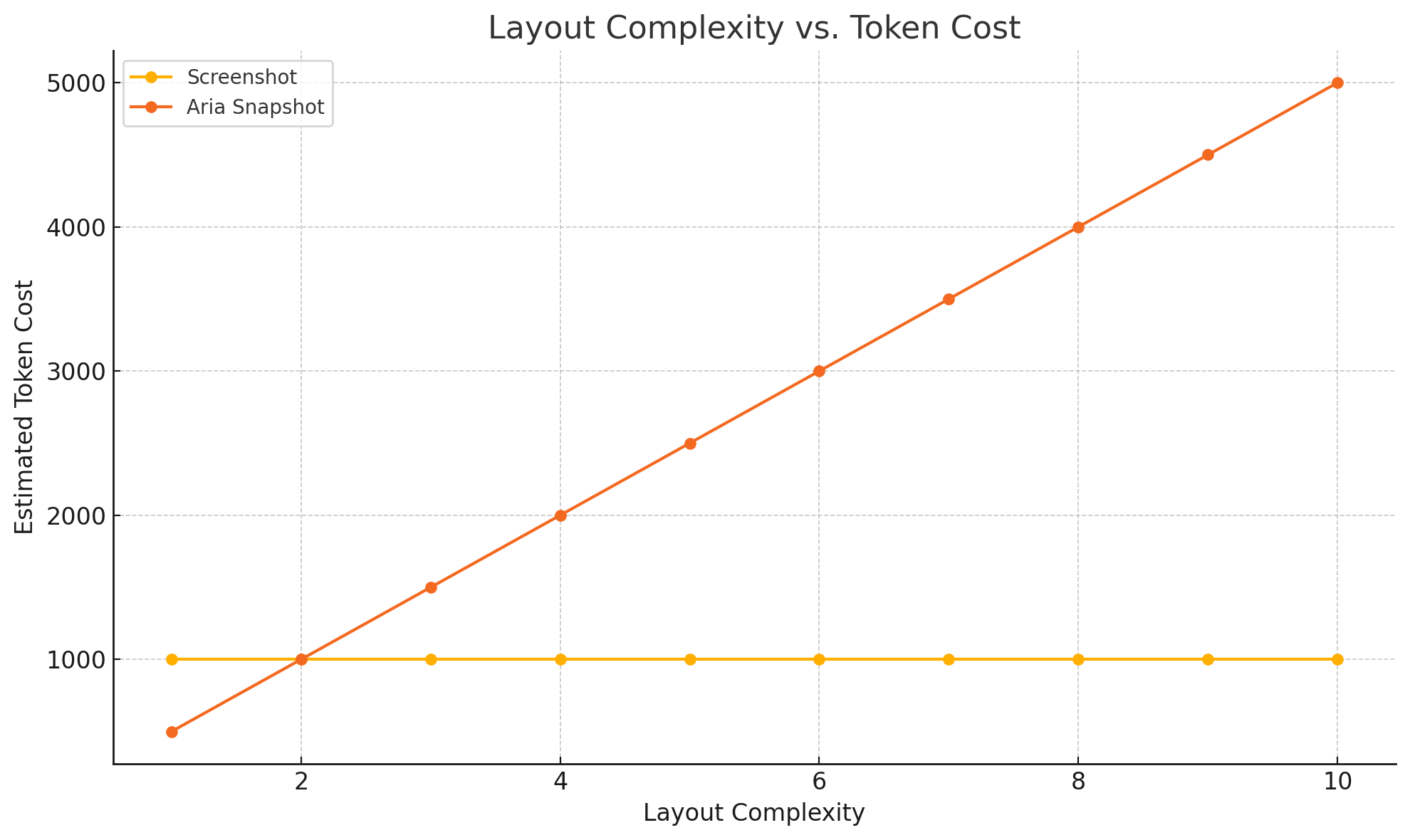
- Screenshots are cheap, but can be inaccurate to action on.
- Aria snapshots can be expensive in tokens if the layout is more complicated, but can have more reliably accuracy.
- Playwright’s built-in
refsupport makes it the best browser automation tool for the job.
In part two, we’ll create an actual agent loop, hook up our own playwright MCP server, and figure out how to optimize our API calls. Spoiler alert—aria snapshots probably aren’t going to be enough
Footnotes
-
You can use tools like OpenAI’s tokenizer to visually count tokens. ↩